05. 데이터 전처리
데이터 전처리
: 사이킷런의 ML 알고리즘을 적용하기 전에 데이터에 대해 미리 처리해야 할 기본 사항
1. 결손값, NaN,null 값은 허용 X
- Null을 고정된 다른 값으로 변환해야 함 (많지 않으면 피처의 평균값 등으로 대체)
- Null값이 대부분이라면 피처를 드랍하는 것이 나음
- 중요도가 높은 피처일 경우, Null을 피처의 평균값으로 대체할 경우 예측 왜곡이 심할 수 있음
2. 사이킷런의 머신러닝 알고리즘은 문자열 값을 입력값으로 허용 X
- 모든 문자열 값은 인코딩 되어 숫자형으로 변환되어야 함
- 문자열 피처는 일반적으로 카테고리형 피처(코드값)와 텍스트형 피처를 의미
- 텍스트형 피처는 *피처 백터화(feature vectorization) 기법으로 벡터화하거나 불필요할 경우 삭제하는것이 좋음
*피처 백터화 : 사전 준비 작업으로 가공된 텍스트에서 피처를 추출하고 여기에 벡터 값을 할당
데이터 인코딩
: 대표적으로 1) 레이블 인코딩(lable encoding)과 2) 원-핫 인코딩(One Hot encoding)

1) 레이블 인코딩 : 카테고리 피처를 코드형 숫자값으로 변환
(*01,02(문자형)안됨, 1,2 숫자형만 가능)
- 레이블 인코딩은 LableEncoder 클래스로 구현함
- LableEncoder를 객체로 생성한 후 **fit()과 transform()을 호출해 레이블 인코딩을 수행함
**fit()과 transform()의 차이
- fit() : 학습데이터셋에서 변환을 위한 기반 설정을 하는 함수, 데이터를 학습시키는 메서드
- transform() : fit()을 기준으로 얻은 조건으로 변형하는 함수
- fit_transform() : 두 개를 합쳐 놓은 것
# 인코딩
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성한 후 , fit( ) 과 transform( ) 으로 label 인코딩 수행.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)
# 디코딩
# inverse_transform()을 통해 인코딩 된 값을 다시 디코딩 할 수 있음
print('디코딩 원본 값:',encoder.inverse_transform([4, 5, 2, 0, 1, 1, 3, 3]))- 레이블 인코딩을 일괄적인 숫자 값으로 변환하면서, 일부 ML 알고리즘에는 이를 적용했을때 예측 성능이 떨어지는 경우가 있음
- 따라서 레이블 인코딩은 선형회귀와 같은 ML 알고리즘에는 적용하지 않아야 함 (트리 계열 ML 알고리즘은 괜찮음)
- 예를 들어, 위 코드에서 냉장고가 1, 믹서가 2로 변환되면 2가 더 큰 값이므로
특정 ML 알고리즘에서 가중치가 더 크게 부여되거나 더 중요하게 인식할 가능성이 발생 - 이런 문제 해결을 위해 원-핫 인코딩 사용
2) 원-핫 인코딩(One-Hot Encoding)
: 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 컬럼에만 1을 표시,나머지에는 0을 표시
- 사이킷런에서 OneHotEncoder 클래스로 변환이 가능함
! 레이블 인코딩과 다르게 주의할 점
- 입력값으로 2차원 데이터가 필요함
- OneHotEncoder를 이용해 변환한 값이 *희소 행렬(Square Matrix)형태이므로
이를 다시 toarray() 메서드를 이용해 **밀집행렬(Dense Matrix)로 변환해야 함
*희소행렬 : 대부분 값이 0으로 채워진 행렬
**밀집행렬 : 대부분의 값이 0이 아닌값들로 채워진 행렬
- 원-핫 인코딩을 더 쉽게 지원하는 API : get_dummies()
사이킷런의 OneHotEncoder와 다르게 문자열 카테고리 값을 숫자 형으로 변환할 필요 없이 바로 변환
피처 스케일링과 정규화
- 피처 스케일링 : 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업
대표적인 방법으로 1)표준화(Standardization)와 2)정규화(Normalization)이 있음
1) 표준화 : 평균이 0, 분산이 1인 가우시안 정규 분포를 가진값으로 변환하는 작업
- StandardScaler : 표준화를 쉽게 지원하기 위한 클래스
개별 피처를 평균이 0 ,분산이 1인 값으로 변환해줌 - 데이터가 가우시안 분포를 가지고 있다고 가정하는
서포트 벡터 머신 (SVM), 선형 회귀, 로지스틱 회귀에서 표준화를 적용하는 것이 중요함
2) 정규화 : 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념
개별 데이터의 크기를 모두 똑같은 단위로 변경
- MinMaxScaler
- 데이터값을 0과 1 사이의 범위 값으로 변환(음수 있으면 -1 에서 1 사이로)
- 데이터의 분포가 가우시안 분포가 아닐 경우에 Min, Max Scale 적용해 볼 수 있음

! Scaler를 이용하여 학습 데이터와 테스트 데이터에 fit(), transform(), fit_transform() 적용 시 유의사항
: 학습 데이터로 fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 하며,
그렇지 않고 테스트 데이터로 다시 새로운 스케일링 기준 정보를 만들게 되면
학습 데이터와 테스트 데이터의 스케일링 기준 정보가 서로 달라지기 때문에 올바른 예측이 힘듦
따라서, test_array에 Scale 변환을 할 때는 반드시 fit()을 호출하지 않고 transform() 만으로 변환해야 함
06. 사이킷런으로 수행하는 타이타닉 생존자 예측
데이터 확인 (titanic_train.csv)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
titanic_df = pd.read_csv('titanic_train.csv')
titanic_df.head(3)
print('\n ### train 데이터 정보 ### \n')
print(titanic_df.info())
*RangeIndex : 인덱스의 범위 = 전체 로우 수, 판다스의 object 타입은 srting 이라고 봐도 무방함
Null 처리
- 사이킷런 머신러닝 알고리즘은 Null 값을 허용하지 않으므로 Null 값을 어떻게 처리할지 결정
: Dataframe의 fillna() 함수를 사용해 간단하게 Null 값을 평균 또는 고정 값으로 변경
- age: 평균 나이, 나머지 컬럼은 : 'N'
- 모든 컬럼에 Null 값이 없는지 재확인
titanic_df['Age'].fillna(titanic_df['Age'].mean(),inplace=True)
titanic_df['Cabin'].fillna('N',inplace=True)
titanic_df['Embarked'].fillna('N',inplace=True)
print('데이터 세트 Null 값 갯수 ',titanic_df.isnull().sum().sum())
## 결과 : 데이터 세트 Null 값 갯수 0
시각화
- seaborn 패키지 이용
- seaborn은 기본적으로 맷플롭립에 기반
- X축 : Sex, Y축 : Survived, Dataframe 객체명을 입력, barplot()함수 호출
# 부에 따른 생존률 + 성별
sns.barplot(x='Pclass', y='Survived', hue='Sex', data=titanic_df)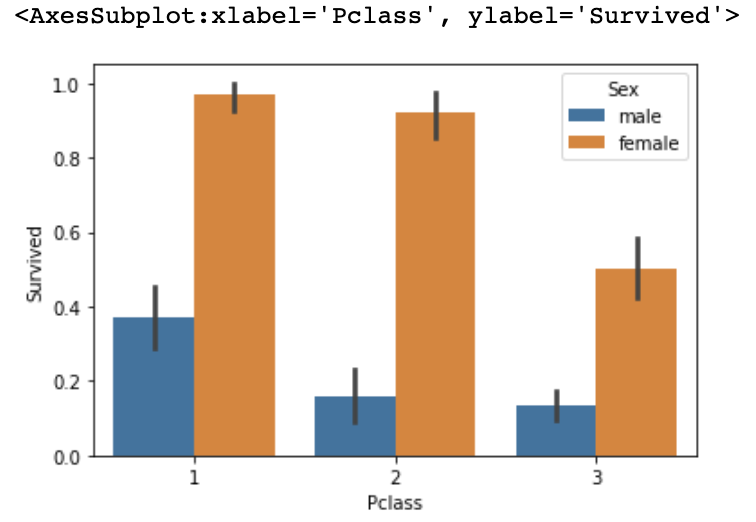
전체 프로세스
함수 생성하여 피처 가공
from sklearn.preprocessing import LabelEncoder
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
df['Fare'].fillna(0, inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 피처 제거
def drop_features(df):
df.drop(['PassengerId', 'Name', 'Ticket'], axis=1, inplace=True)
return df
# 레이블 인코딩 수행 : 사이킷런의 LabelEncoder 클래스를 이용
# 문자열 카테고리 피처를 숫자형 카테고리 피처로 변환
# LabelEncoder 객체는 카테고리 값의 유형 수에 따라 0~(카테고리 유형수-1)까지의 숫자값으로 변환
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 데이터 전처리 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
데이터셋 생성
# 원본 데이터를 재로딩 하고, feature데이터 셋과 Label 데이터 셋 추출
titanic_df = pd.read_csv('titanic_train.csv')
# Survived 속성만 따로 분리하여 클래스 결정값 데이터로 만듦
y_titanic_df = titanic_df['Survived']
# Survived 속성만 드롭하여 데이터셋 생성
X_titanic_df= titanic_df.drop('Survived',axis=1)
# transform_features()를 적용하여 데이터 가공
X_titanic_df = transform_features(X_titanic_df)# train_test_split() API를 이용하여 별도의 테스트 데이터셋 추출
# 테스트 데이터셋의 크기는 전체의 20%
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X_titanic_df, y_titanic_df, \
test_size=0.2, random_state=11)
사이킷런 Classifier 클래스 생성 (결정트리, Random Forest, 로지스틱 회귀)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 결정트리, Random Forest, 로지스틱 회귀를 위한 사이킷런 Classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression(solver='liblinear')
# LIBLINEAR: A Library for Large Linear Classification
# solver='liblinear' 는 로지스틱 회귀의 최적화 알고리즘을 liblinear로 설정
# 일반적으로 작은 데이터셋에서의 이진 분류는 liblinear가 성능이 좀 더 좋은 경향이 있음
# DecisionTreeClassifier 학습/예측/평가
dt_clf.fit(X_train , y_train)
dt_pred = dt_clf.predict(X_test)
print('DecisionTreeClassifier 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
# RandomForestClassifier 학습/예측/평가
rf_clf.fit(X_train , y_train)
rf_pred = rf_clf.predict(X_test)
print('RandomForestClassifier 정확도:{0:.4f}'.format(accuracy_score(y_test, rf_pred)))
# LogisticRegression 학습/예측/평가
lr_clf.fit(X_train , y_train)
lr_pred = lr_clf.predict(X_test)
print('LogisticRegression 정확도: {0:.4f}'.format(accuracy_score(y_test, lr_pred)))
결정 트리 모델 추가 평가 (KFOLD, cross_val_score(), GridSearchCV() 사용)
1) KFOLD
# KFOLD (K=5)
from sklearn.model_selection import KFold
def exec_kfold(clf, folds=5):
# 폴드 세트를 5개인 KFold객체를 생성, 폴드 수만큼 예측결과 저장을 위한 리스트 객체 생성.
kfold = KFold(n_splits=folds)
scores = []
# KFold 교차 검증 수행.
for iter_count , (train_index, test_index) in enumerate(kfold.split(X_titanic_df)):
# X_titanic_df 데이터에서 교차 검증별로 학습과 검증 데이터를 가리키는 index 생성
X_train, X_test = X_titanic_df.values[train_index], X_titanic_df.values[test_index]
y_train, y_test = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
# Classifier 학습, 예측, 정확도 계산
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
scores.append(accuracy)
print("교차 검증 {0} 정확도: {1:.4f}".format(iter_count, accuracy))
# 5개 fold에서의 평균 정확도 계산.
mean_score = np.mean(scores)
print("평균 정확도: {0:.4f}".format(mean_score))
# exec_kfold 호출
exec_kfold(dt_clf , folds=5)평균 정확도 : 0.7823
2) cross_val_score
from sklearn.model_selection import cross_val_score
# cross_val_score가 stratifiedKFold 이용
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv=5)
for iter_count, accuracy in enumerate(scores):
print("교차검증 {0} 정확도: {1:.4f}".format(iter_count, accuracy))
print("평균 정확도: {0:.4f}".format(np.mean(scores)))평균 정확도 : 0.7879
3) GridSearchCV
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[2,3,5,10],
'min_samples_split':[2,3,5], 'min_samples_leaf':[1,5,8]}
grid_dclf = GridSearchCV(dt_clf , param_grid=parameters , scoring='accuracy' , cv=5)
grid_dclf.fit(X_train , y_train)
print('GridSearchCV 최적 하이퍼 파라미터 :',grid_dclf.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dclf.best_score_))
best_dclf = grid_dclf.best_estimator_
# GridSearchCV의 최적 하이퍼 파라미터로 학습된 Estimator로 예측 및 평가 수행.
dpredictions = best_dclf.predict(X_test)
accuracy = accuracy_score(y_test , dpredictions)
print('테스트 세트에서의 DecisionTreeClassifier 정확도 : {0:.4f}'.format(accuracy))#결과
GridSearchCV 최적 하이퍼 파라미터 : {'max_depth': 3, 'min_samples_leaf': 5, 'min_samples_split': 2}
GridSearchCV 최고 정확도: 0.7992
테스트 세트에서의 DecisionTreeClassifier 정확도 : 0.8715# 해석
: 하이퍼 파라미터 변경 전보다 정확도가 8% 이상 증가 -> 테스트용 데이터셋이 작아 수치상으로 예측성능이 많이 증가한 것처럼 보임
'머신러닝' 카테고리의 다른 글
| [3장] 파이썬 머신러닝 완벽 가이드_평가_2 (0) | 2023.05.13 |
|---|---|
| [3장] 파이썬 머신러닝 완벽가이드_평가_1 (1) | 2023.05.05 |
| [2장] 파이썬 머신러닝 완벽 가이드_사이킷런_1 (0) | 2023.04.21 |
| [1장] 파이썬 머신러닝 완벽 가이드_Pandas (1) | 2023.04.14 |
| [1장] 파이썬 머신러닝 완벽 가이드_Numpy (1) | 2023.04.14 |