[1장] 파이썬 머신러닝 완벽 가이드_Pandas
Pandas
- 행과 열로 이루어진 2차원의 데이터를 효율적으로 가공/처리
- 넘파이가 저수준 API가 대부분
- 넘파이를 기반으로 작성된 판다스는 넘파이보다 훨씬 유연하고 편리하게 데이터 핸들링 가능
- 판다스는 여러형태의 데이터를 DataFrame으로 변경해 데이터 가공/분석 편리
DataFrame
- 판다스의 핵심 개체
- DataFrame은 여러개의 행과 열로 이루어진 2차원 데이터를 담는 구조체
- Index , Series 로 구성
- Index는 Primary key처럼 개별 데이터를 고유하게 식별하는 키
- Series와 DataFrame은 모두 Index를 키값으로 가지고 있음
- Series와 DataFrame의 가장 큰 차이는 Series는 컬럼이 하나, Dataframe은 여러개
- DataFrame은 여러개의 Series로 이루어졌다고 할 수 있음
import pandas as pd
csv 파일 불러오기
- read_csv() :csv 파일 포맷 변환을 위한 API
- read_csv() 와 read_table()의 가장 큰 차이는 필드 구분 문자(Delimeter)가 콤마 or 탭
- read_csv()의 필드 구분자는 콤마 / read_table()의 디폴트 필드 구분자는 탭
- read_csv()는 csv 뿐만 아니라 어떤 필드 구분 문자 기반의 파일 포맷도 DataFrame으로 변환 가능
- read_csv()의 인자인 sep에 해당 구분 문자 입력하면 됨
ex. 탭일 경우 read_csv('파일명', sep='\t') - sep 인자 생략하면 자동으로 콤마 할당
- filepath : 로드하려는 데이터 파일의 경로를 포함한 파일명 입력
- 현재 자신의 path 확인
import os
path = os.getcwd()
print(path)
Data 확인하기 (Ex. Titanic Data)
titanic_df = pd.read_csv('titanic_train.txt') #데이터 로드
print('titanic 변수 type:',type(titanic_df)) # type 확인
titanic_df # 891 rows × 12 columns 임을 확인할 수 있음
head()
- 기본 5행 출력
- ()안에 원하는 숫자 넣어 미리 몇 행 보고싶은지 설정
shape
- DataFrame의 행과 열 크기 확인, DataFrame의 행과 열을 튜플 형태로 반환
info()
- 컬럼 타입, null 데이터 개수, 데이터 분포도 등의 메타 데이터도 조회
describe()
- describe()메서드는 컬럼별 숫자형 데이터값의 n-percentile 분포도, 평균값, 최댓값, 최솟값
- describe()메서드는 오직 숫자형(int, float 등) 컬럼의 분포도만 조사하며 자동으로 object 타입의 컬럼은 출력에서 제외
value counts()
- DataFrame의 []연산자 내부에 컬럼명 입력하면 Series 형태로(인덱스 + 컬럼 하나) 특정 컬럼 데이터 세트가 반환됨
- 반환된 Series 객체에 value_counts()메서드 호출하면 해당 컬럼 유형, 건수 확인 가능
- value_counts() 는 지정된 컬럼의 데이터값 건수 반환, 데이터 분포도 확인하는데 유용함
- 많은 건수 순서로 정렬되어 값을 반환함
- value_counts()는 null 값을 무시하고 결괏값을 내놓기 쉽다는 점을 유의
- value_counts()는 null 값을 포함할지를 dropna 인자로 판단함
- dropna의 기본값은 true이며 null값을 무시하고 건수 계산
- value_counts()는 디폴트로 dropna=True이므로 value_counts(dropna=True)와 동일
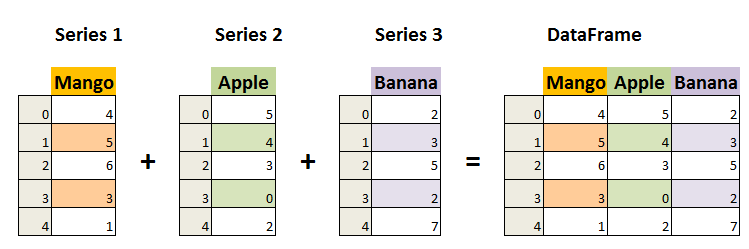
DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
list ---> ndarray
col_name1=['col1']
list1 = [1, 2, 3]
array1 = np.array(list1) # array 함수로 리스트 받아서 ndarray로 변환
print('array1 shape:', array1.shape )

list ---> dataframe
# 리스트를 이용해 DataFrame 생성
df_list1 = pd.DataFrame(list1, columns=col_name1)
print('1차원 리스트로 만든 DataFrame:\n', df_list1)

ndarray ---> dataframe
# 넘파이 ndarray를 이용해 DataFrame 생성
df_array1 = pd.DataFrame(array1, columns=col_name1)
print('1차원 ndarray로 만든 DataFrame:\n', df_array1)
dictionary* ---> dataframe (*dictionary : 사전형 데이터를 의미, key와 value를 1대1로 대응시킨 형태)
# Key는 컬럼명으로 매핑, Value는 리스트 형(또는 ndarray)
dict = {'col1':[1, 11], 'col2':[2, 22], 'col3':[3, 33]}
df_dict = pd.DataFrame(dict)
print('딕셔너리로 만든 DataFrame:\n', df_dict)

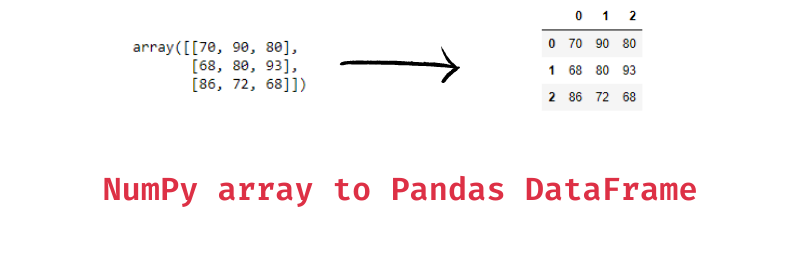
dictionary ---> ndarray
# DataFrame을 ndarray로 변환 : values 사용
array3 = df_dict.values
print('df_dict.values 타입:', type(array3), 'df_dict.values shape:', array3.shape)
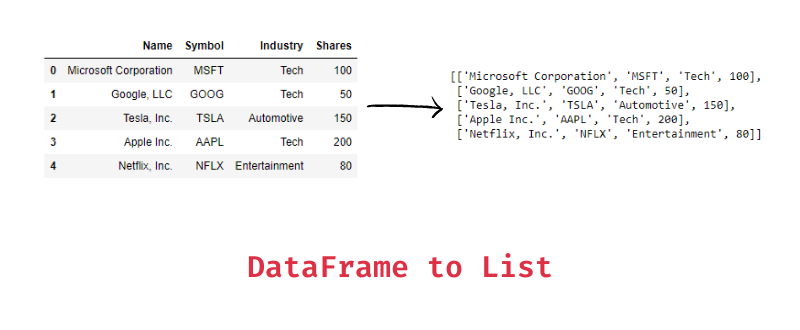
print(array3)dataframe ---> list
#values로 얻은 ndarray에 tolist()를 호출
list3 = df_dict.values.tolist()print('df_dict.values.tolist() 타입:', type(list3))
print(list3)
DataFrame ---> dictionary
# DataFrame 객체의 to_dict() 메서드를 호출하는데, 인자로 'list'를 입력하면 딕셔너리의 값이 리스트로 반환됨
dict3 = df_dict.to_dict('list')
print('\n df_dict.to_dict() 타입:', type(dict3))
print(dict3)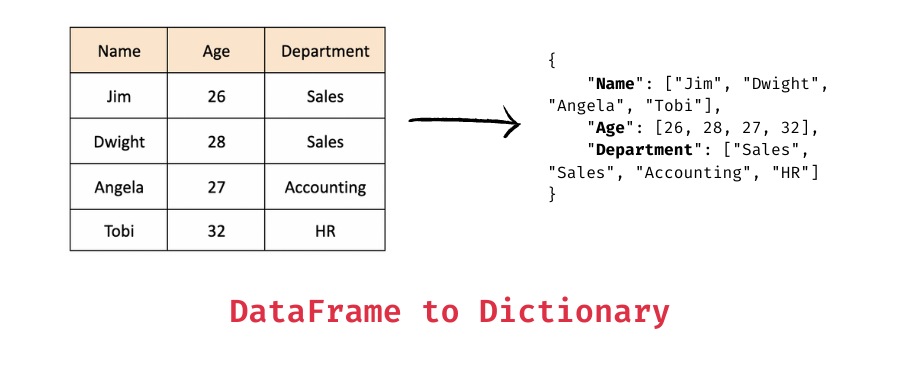
DataFrame의 컬럼 데이터셋 Acess
- 새로운 컬럼 추가 및 값 할당
titanic_df['Age_0']=0
- 값 업데이트
titanic_df['Age_by_10'] = titanic_df['Age_by_10'] + 100
dataframe 데이터 삭제
- DataFrame.drop(lables=None, axis=0, columns=None, level=None, inplace=False, errors='raise')
- axis 0 : 행방향 축 / axis 1 : 컬럼 방향 축
- 판다스의 DataFrame은 2차원 데이터만 다루므로 axis0,1 만 존재
- drop()메서드에 axis=1을 입력하면 칼럼 축 방향으로 드롭 수행 -> 컬럼을 드롭하겠다
inplace
- inplace의 디폴트 값이 false -> 자기 자신의 DataFrame의 데이터는 삭제하지 않음
- inplace = True로 설정하면 자신의 DataFrame 데이터도 삭제함
- 여러개 삭제하고 싶으면 리스트 형태로 삭제하고자 하는 컬럼명을 입력해 lables 파라미터로 입력
- inplace = True로 설정하면 반환값은 None이 됨 -> 반환값을 다시 자신의 DataFrame에 할당하면 안됨
index
- index 객체는 함부로 변경할 수 없음
- seriesa 객체는 index 객체를 포함하지만 series 객체에 연산 함수를 적용할때 index는 연산에서 제외됨
- index는 오직 식별용으로만 사용
- DataFrame 및 Series에 reset_index() 메서드를 수행하면 새롭게 인덱스를 연속 숫자형으로 할당, 기존 인덱스는 'index'라는 새로운 컬럼명으로 추가
데이터 셀렉션 및 필터링
- DataFrame의 [ ] 연산자
: DataFrame 뒤에 있는 []는 컬럼만 지정 가능, 숫자 안됨 (KeyError 오류 발생) - 불린 인덱싱도 가능
iloc[ ] 과 loc[ ]
iloc[ ]
- 위치 기반 인덱싱 방식으로 동작
- 위치 기반 인덱싱은 행과 열 위치를, 0을 출발점으로 하는 세로축, 가로축 좌표 정숫값으로 지정
- # iloc[행 위치 정숫값, 열 위치 정숫값] -> [] 안에 숫자만 가능
loc[ ]
- loc[]은 명칭(lable)기반으로 데이터 추출
- 행 위치에는 DataFrame 인덱스 값을, 열 위치에는 컬럼명 입력 = loc[인덱스값, 컬럼명]
- loc[]에 슬라이싱 기호 ':' 적용시 유의사항
일반 슬라이싱은 '시작값:종료값' : 시작값~종료값-1 인데, loc[]은 명칭 기반으로 -1이 불가능하여 '시작값:종료값' : 시작값~종료값
불린인덱싱
iloc[]에서는 불가능
기본 연산 기호 : and : & , or : | , Not : ~
조건이 여러개인 경우, 개별 조건을 변수에 할당하고 변수를 결합해서 불린 인덱싱 수행 가능
cond1 = titanic_df['Age'] > 60
cond2 = titanic_df['Pclass']==1
cond3 = titanic_df['Sex']=='female'
titanic_df[ cond1 & cond2 & cond3]
정렬
- DataFrame, Series의 정렬 - sort_values()
- by : 특정 컬럼, ascending = True : 오름차순
Aggregation
- Aggregation 함수 적용 (max, min, sum, count ..)
- DataFrame에서 바로 aggregation을 호출할 경우 모든 컬럼에 해당 aggregation을 적용
- count()를 적용하면 모든 컬럼에 cnount() 결과 반환
- 단,count()는 Null 값을 반영하지 않은 결과 반환
groupby()
groupby()한 결과에서 원하는 컬럼만 필터링 후 count
titanic_groupby = titanic_df.groupby('Pclass')[['PassengerId', 'Survived']].count()
titanic_groupby*SQL과 비교
- sql : select max(Age), min(Age) from titanic_table group by Pclass
- pandas : titanic_df.groupby('Pclass')['Age'].agg([max, min])
결손 데이터
- 결손 데이터는 컬럼에 값이 없는 NULL 인 경우 의미, 넘파이의 NaN으로 표시함
- 머신러닝 알고리즘은 NaN 값을 처리하지 않으므로, 다른값으로 대체해야함
- Nan은 평균, 총합 등의 함수 연산 시 제외됨
- NaN여부 확인 : isna(), NaN 값을 다른값으로 대체 : fillna()
- 결손 데이터의 개수 확인
isna -> True = 1 이므로 sum() 이용하여 구함
- Missing 데이터 대체하기 : fillna( )
- *주의 : fillna()를 이용해 반환 값을 다시 받거나 inplace=True 파라미터를 fillna()에 추가해야 실제 데이터셋의 값이 변경됨
apply lambda로 데이터 가공
- 판다스는 apply 함수에 lambda 식을 결합해서 DataFrame이나 Series의 레코드 별로 데이터를 가공하는 기능을 제공함
- ':' 로 입력 인자와 반환된 인자의 계산식을 분리함 , 왼: 입력인자, 오: 반환인자
lambda_square = lambda x : x ** 2
print('3의 제곱은:',lambda_square(3))- 입력인자가 여러개인 경우 map() 함수를 결합해서 사용
a=[1,2,3]
squares = map(lambda x : x**2, a)
list(squares)- lambda식에서 if else 사용시 주의 사항
- ':' 오른쪽에 반환값이 있어야함
- else if 는 지원하지 않음